Learn about our leading AI models
Discover the AI models behind our most impactful innovations, understand their capabilities, and find the right one when you're ready to build your own AI project.
-

Agentic Multimodal Text Code Image Audio
Gemini 2.5 Pro Preview
Best for coding and complex prompts.
State-of-the-art in key math and science benchmarks.
Easily generate code for web development tasks.
Understands input across text, audio, images and video.
Explore vast datasets with a 1-million token context window.
-

Agentic Multimodal Text Code Image Audio
Gemini 2.5 Flash Preview
Best for fast performance on complex tasks.
Control how much 2.5 Flash reasons to reduce latency and cost.
Understands input across text, audio, images and video.
Explore vast datasets with a 1-million token context window.
-

Agentic Ready for developers Multimodal Text Code Image Audio
Gemini 2.0 Flash
Our powerful workhorse model with low latency and enhanced performance, built to power agentic experiences.
Create or edit images and seamlessly blend them with text.
Easily steer Gemini’s speaking style to match any mood.
Build agents that use Google Search, code execution and more.
-

Ready for Developers Multimodal Text Code Image Audio
Gemini 2.0 Flash-Lite
Best for cost-efficient performance.
Better quality than 1.5 Flash, at the same speed and cost.
A 1 million token context window and multimodal input.
-

Ready for Developers Multimodal Text Code Image Audio
Gemini 1.5 Flash
Our lightweight model, optimized for tasks where speed and efficiency matter the most.
Sub-second average first-token latency for the vast majority of developer and enterprise use cases.
On most common tasks, 1.5 Flash models achieve comparable quality to larger models, at a fraction of the cost.
Process hours of video and audio, and hundreds of thousands of words or lines of code.
-

Ready for developers Multimodal Text Code
Gemini 1.5 Pro
Our best model for reasoning across large amounts of information.
Can seamlessly analyze, classify and summarize large amounts of content within a given prompt.
Can perform highly sophisticated understanding and reasoning tasks for different modalities.
When given a prompt with more than 100,000 lines of code, it can better reason across examples, suggest helpful modifications and give explanations about how different parts of the code works.
-
Ready for developers Multimodal Text Code
Gemini 1.0 Pro
Our model for scaling across a wide range of tasks.
Fine-tuned both to be a coding model to generate proposal solution candidates, and to be a reward model that is leveraged to recognize and extract the most promising code candidates.
Significantly outperforms the USM and Whisper models across all ASR and AST tasks, both for English and multilingual test sets.
-
Ready for developers Multimodal Text Code
Gemini 1.0 Ultra
Our largest model for highly complex tasks.
Natively understands and reasons across sequences of audio, images, and text.
Excels at coding and achieves state-of-the-art performance when integrated into AlphaCode 2.
Advanced analytical capabilities and strong performance on competition-grade problem sets.
-

Ready for developers Multimodal Text Code
Gemini 1.0 Nano
Our most efficient model for on-device tasks.
Excels at on-device tasks, such as summarization, reading comprehension, text completion tasks, and exhibits impressive capabilities in reasoning, STEM, coding, multimodal, and multilingual tasks relative to their sizes.
With capabilities accessible to a larger set of platforms and devices, the Gemini models expand accessibility to everyone.
-

Open models Ready for developers Text
Gemma
A family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models.
Incorporating comprehensive safety measures, these models help ensure responsible and trustworthy AI solutions through curated datasets and rigorous tuning.
Gemma models achieve exceptional benchmark results at its 2B and 7B sizes, even outperforming some larger open models.
With Keras 3.0, enjoy seamless compatibility with JAX, TensorFlow, and PyTorch, empowering you to effortlessly choose and switch frameworks depending on your task.
-

Open models Ready for developers Code
CodeGemma
A collection of lightweight open code models built on top of Gemma. CodeGemma models perform a variety of tasks like code completion, code generation, code chat, and instruction following.
Complete lines, functions, and even generate entire blocks of code, whether you're working locally or using Google Cloud resources.
Trained on 500 billion tokens data from web documents, mathematics, and code. Generates code that's not only more syntactically correct but also semantically meaningful, reducing errors and debugging time.
Supports Python, JavaScript, Java, Kotlin, C++, C#, Rust, Go, and other languages.
-

Open models Ready for developers Text
RecurrentGemma
A technically distinct model that leverages recurrent neural networks and local attention to improve memory efficiency.
Lower memory requirements allow for the generation of longer samples on devices with limited memory, such as single GPUs or CPUs.
Can perform inference at significantly higher batch sizes, thus generating substantially more tokens per second (especially when generating long sequences).
Showcases a non-transformer model that achieves high performance, highlighting advancements in deep learning research.
-

Open models Ready for developers Text
PaliGemma
Our first multimodal Gemma model, designed for class-leading fine-tune performance across diverse vision-language tasks.
Designed for class-leading fine-tune performance on a wide range of vision-language tasks like:
- image and short video captioning
- visual question answering
- understanding text in images
- object detection
- and object segmentation
Supports a wide range of languages.
-
Ready for developers Text Code
PaLM 2
A next generation language model with improved multilingual, reasoning and coding capabilities.
Demonstrates improved capabilities in logic, common sense reasoning, and mathematics.
Improved its ability to understand, generate and translate nuanced text — including idioms, poems and riddles. PaLM 2 also passes advanced language proficiency exams at the “mastery” level.
Excels at popular programming languages like Python and JavaScript, but is also capable of generating specialized code in languages like Prolog, Fortran, and Verilog.
-

Ready for developers Image
Imagen
A family of text-to-image models able to generate high-quality images and understand prompts written in natural language.
Able to generate images in a wide range of visual styles, with rich lighting and capturing even small details thanks to advancements in modeling techniques.
Text-to-image models often struggle to include text accurately. Imagen 3 improves this process, ensuring the correct words or phrases appear in the generated images.
Imagen 3 understands prompts written in natural, everyday language, making it easier to get the output you want without complex prompt engineering.
Includes built-in safety precautions to help ensure that generated images align with Google’s Responsible AI principles.
-
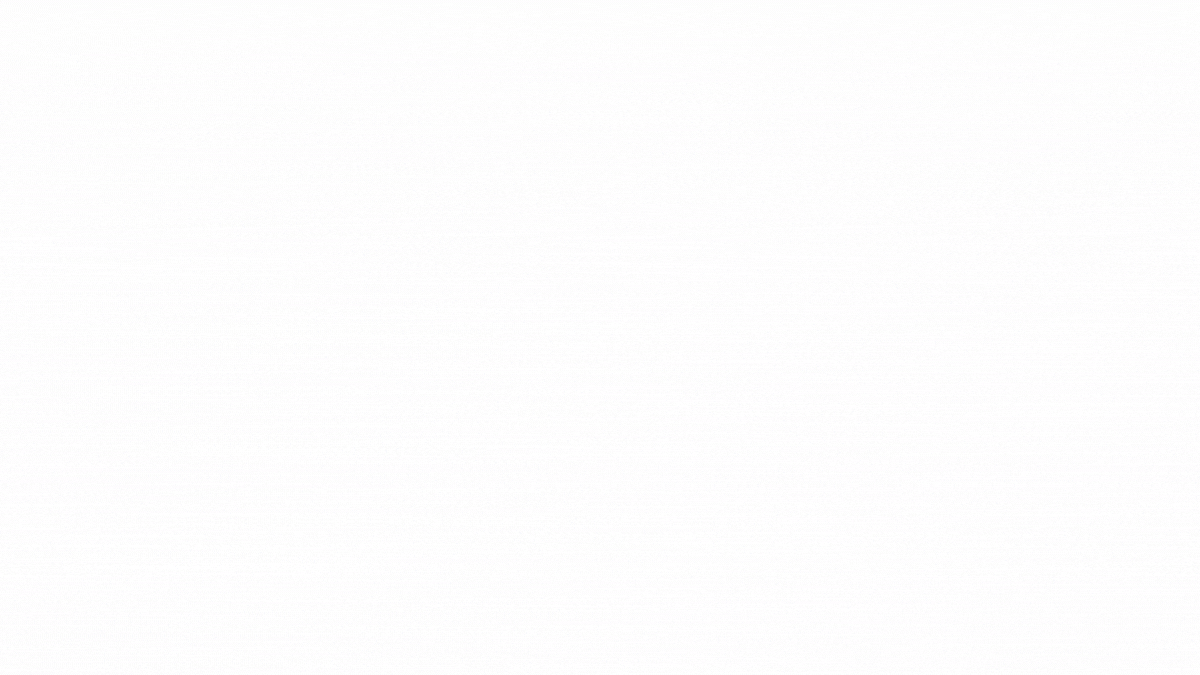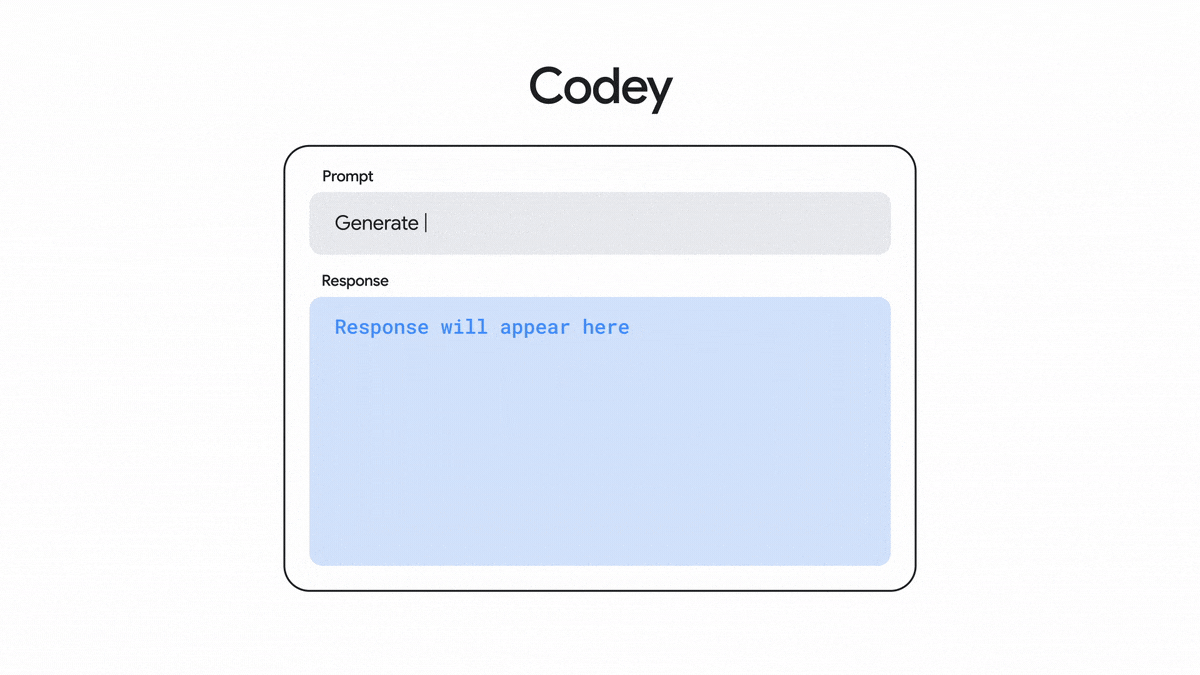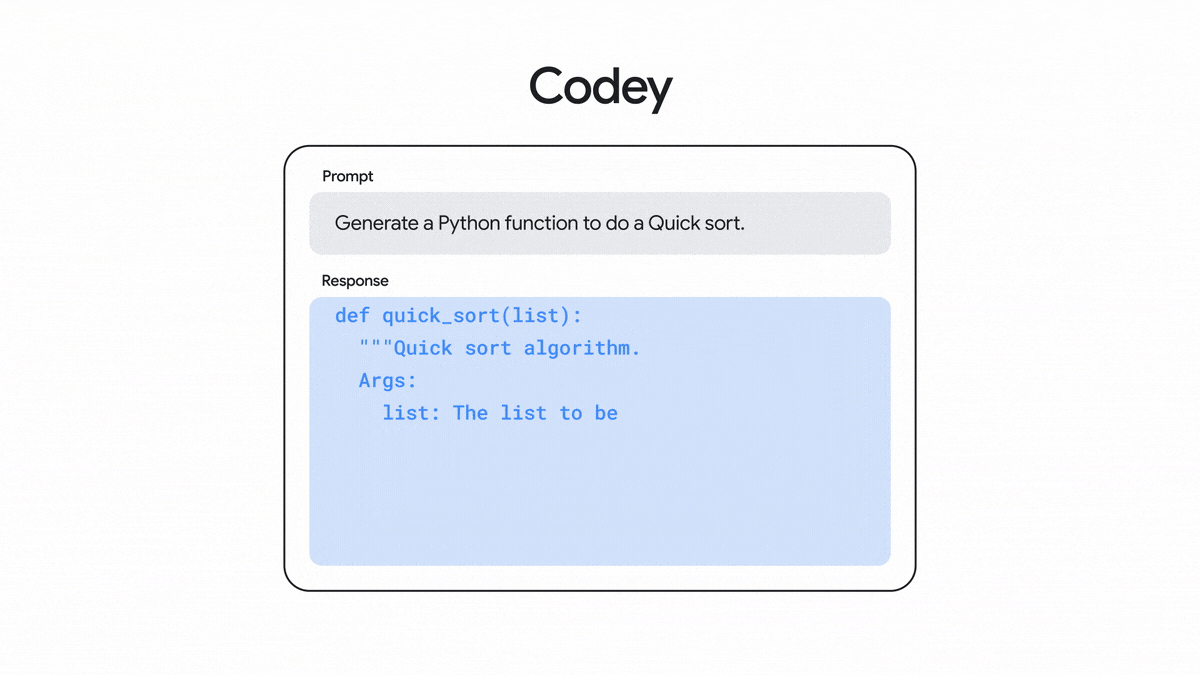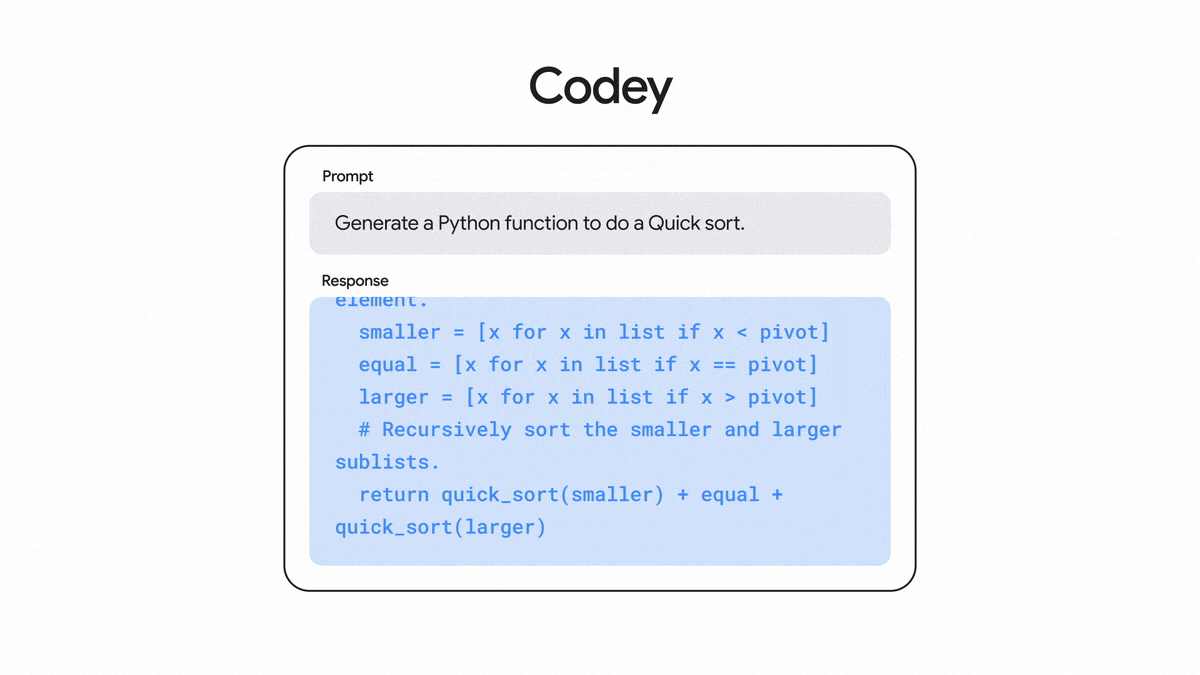
Ready for developers Code
Codey
A family of models that generate code based on a natural language description. It can be used to create functions, web pages, unit tests, and other types of code.
Suggests the next few lines based on the existing context of code.
Generates code based on natural language prompts from a developer.
Lets developers converse with a bot to get help with debugging, documentation, learning new concepts, and other code-related questions.
-
Ready for developers Text
Chirp
A family of universal Speech Models trained on 12 million hours of speech to enable automatic speech recognition (ASR) for 100+ languages.
Can transcribe in over 100 languages with excellent speech recognition.
Achieves state-of-the-art Word Error Rate (WER) on a variety of public test sets and languages. It delivers 98% speech recognition accuracy in English and over 300% relative improvement in several languages with less than 10M speakers.
Chirp's 2-billion-parameter model outpaces previous speech models to deliver superior performance.
-

Video
Veo
Our most capable generative video model. A tool to explore new applications and creative possibilities with video generation.
With just text prompts, it creates high-quality, 1080P videos that can go beyond 60 seconds. Lets you control the camera, and prompt for things like time lapse or aerial shots of a landscape.
Interprets and visualizes the tone of prompts. Subtle cues in body language, lighting, and even color choices could dramatically shift the look of a generated video.
Able to retain visual consistency in appearance, locations and style across multiple scenes in a longer video.
Veo allows users to edit videos through prompts, including modifying, adding or replacing visual elements and it can generate a video from an image input, using the image to fit within any frame of the output and the prompt as guidance for how the video should proceed.
-

Healthcare Ready for developers Text
MedLM
A family of models fine-tuned for the healthcare industry.
Revolutionizes the way medical information is accessed, analyzed, and applied. Reduces administrative burdens and helps synthesize information seamlessly.
MedLM is a customizable solution that can embed into your workflow and integrate with your data to augment your healthcare capabilities.
Born from a belief that together, technology and medical experts can innovate safely, MedLM helps you stay on the cutting edge.
-

Education Text
LearnLM
A family of models fine-tuned for learning and based on Gemini, infused with education capabilities and grounded in pedagogical evaluations.
Allow for practice and healthy struggle with timely feedback.
Present relevant, well-structured information in multiple modalities.
Dynamically adjust to goals and needs, grounding in relevant materials.
Inspire engagement to provide motivation through the learning journey.
Plan, monitor and help the learner reflect on progress.
-
Cybersecurity Text
SecLM
A security-specialized AI API that combines multiple models, business logic, retrieval, and grounding into a cohesive system that is tuned for security-specific tasks.
Tuned, trained and grounded in threat intelligence from Google, VirusTotal, and Mandiant to bring up-to-date security information and context to users.
Gemini in Security agents use SecLM to help defenders protect their organizations.
Cybersecurity professionals can easily make sense of complex information and perform specialized tasks and workflows.
Ready to build?
Explore developer toolsResponsibility is the bedrock of all of our models.
AI is helping us deliver on our mission in exciting new ways, yet it's still an emerging technology that surfaces new challenges and questions as it evolves.
To us, building AI responsibly means both addressing these challenges and questions while maximizing the benefits for people and society. In navigating this complexity, we’re guided by our AI Principles and cutting-edge research, along with feedback from experts, users, and partners.
These efforts are helping us continually improve our models with new advances like AI-assisted redteaming and prevent their misuse with technologies like SynthID. They are also unlocking exciting, real-world progress towards some of society’s most pressing challenges like predicting floods and accelerating research on neglected diseases.

*SynthID helps identify AI-generated content by embedding an imperceptible watermark on text, images, audio, and video content generated by our models.