Software engineering and programming languages
Software engineering and programming language researchers at Google study all aspects of the software development process, from the engineers who make software to the languages and tools that they use.
About the team
We are a collection of teams from across the company who study the problems faced by engineers and invent new technologies to solve those problems. Our teams take a variety of approaches to solve these problems, including empirical methods, interviews, surveys, innovative tools, formal models, predictive machine learning modeling, data science, experiments, and mixed-methods research techniques. As our engineers work within the largest code repository in the world, the solutions need to work at scale, across a team of global engineers and over 2 billion lines of code.
We aim to make an impact internally on Google engineers and externally on the larger ecosystem of software engineers around the world.
Team focus summaries
Google provides its engineers’ with cutting edge developer tools that operate on codebase with billions of lines of code. The tools are designed to provide engineers with a consistent view of the codebase so they can navigate and edit any project. We research and create new, unique developer tools that allow us to get the benefits of such a large codebase, while still retaining a fast development velocity.
We aim to understand diversity and inclusion challenges facing software developers and evaluate interventions that move the needle on creating an inclusive and equitable culture for all.
We use both qualitative and quantitative methods to study how to make engineers more productive. Google uses the results of these studies to improve both our internal developer tools and processes and our external offerings for developers on GCP and Android.
We build static and dynamic analysis tools that find and prevent serious bugs from manifesting in both Google’s and third-party code. We also leverage this large-scale analysis infrastructure to refactor Google’s code at scale.
We apply deep learning to Google’s large, well-curated codebase to automatically write code and repair bugs.
We design, evaluate, and implement new features for popular programming languages like Java, C++, and Go through their standards’ processes.
We design, implement and evaluate tools and frameworks to automate the testing process and integrate tests with the Google-wide continuous integration infrastructure.
Featured publications
Highlighted work
-
 Software engineering at Google: Lessons Learned from Programming Over TimeA book on how Google manages an ultra-large scale, living codebase that evolves and responds to changing requirements and demands over time.
Software engineering at Google: Lessons Learned from Programming Over TimeA book on how Google manages an ultra-large scale, living codebase that evolves and responds to changing requirements and demands over time. -
 Why Google Stores Billions of Lines of Code in a Single RepositoryPresentation at the @Scale conference in 2015 on why Google stores all the code in a single codebase and the tools we have created to manage it.
Why Google Stores Billions of Lines of Code in a Single RepositoryPresentation at the @Scale conference in 2015 on why Google stores all the code in a single codebase and the tools we have created to manage it. -
 Keeping 2 billion lines of code moving forwardPresentation at the @Scale conference in 2017 on how we keep velocity up in a large scale codebase.
Keeping 2 billion lines of code moving forwardPresentation at the @Scale conference in 2017 on how we keep velocity up in a large scale codebase. -
 2019 Accelerate State of DevOps ReportIndustry-standard report that to helps teams and organizations benchmark themselves against the industry and identify key capabilities to become high performers.
2019 Accelerate State of DevOps ReportIndustry-standard report that to helps teams and organizations benchmark themselves against the industry and identify key capabilities to become high performers. -
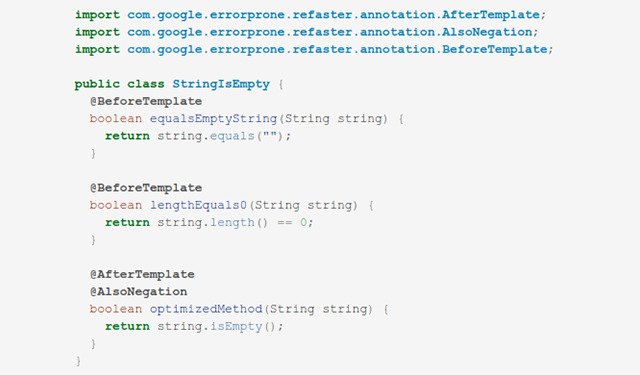 Error ProneGoogle’s standard static analysis tool for Java and the foundation for our refactoring infrastructure. We use a data-driven approach to refine checks and develop new ones. We describe the development of one such check (and some of the challenges we faced for large-scale deployment) in our publication “Detecting argument selection defects” (OOPSLA 2017).
Error ProneGoogle’s standard static analysis tool for Java and the foundation for our refactoring infrastructure. We use a data-driven approach to refine checks and develop new ones. We describe the development of one such check (and some of the challenges we faced for large-scale deployment) in our publication “Detecting argument selection defects” (OOPSLA 2017).
Some of our locations







Some of our people
-

Andrew Macvean
- Human-Computer Interaction and Visualization
- Software Systems
-

Caitlin Sadowski
- Data Management
- Human-Computer Interaction and Visualization
- Software Engineering
-

Charles Sutton
- Machine Intelligence
- Natural Language Processing
- Software Engineering
-

Ciera Jaspan
- Software Engineering
- Software Systems
-

Domagoj Babic
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Software Systems
-

Emerson Murphy-Hill
- Human-Computer Interaction and Visualization
- Software Engineering
-

Franjo Ivancic
- Algorithms and Theory
- Software Engineering
- Security, Privacy and Abuse Prevention
-

John Penix
- Software Engineering
-

Kathryn S. McKinley
- Distributed Systems and Parallel Computing
- Hardware and Architecture
- Software Engineering
-

Marko Ivanković
- Software Engineering
- Software Systems
-

Martín Abadi
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Machine Intelligence
-

Hans-Juergen Boehm
- Software Systems
-

Hyrum Wright
- Software Engineering
-

Lisa Nguyen Quang Do
- Human-Computer Interaction and Visualization
- Software Engineering
- Security, Privacy and Abuse Prevention
-

John Field
- Distributed Systems and Parallel Computing
- Software Systems
-

Danny Tarlow
- Machine Intelligence
- Software Engineering
-

Petros Maniatis
- Machine Intelligence
- Mobile Systems
- Software Engineering
-

Albert Cohen
- Distributed Systems and Parallel Computing
- Machine Intelligence
- Software Engineering
-

Kaiyuan Wang
- Software Engineering
-

Dustin C Smith
- Human-Computer Interaction and Visualization
- Software Engineering
-
Harini Sampath
- Human-Computer Interaction and Visualization
-

Phitchaya Mangpo
- Machine Intelligence
- Software Systems
